가루 삼겹살에 이은 가루 데이터(by Python-Pandas)
침착맨의 가루삽겹살, 사실은 코딩에도 있었다?



침착맨이라는 스트리머가 어느 날 재미로 사업 구상 아이디어를 하나 냈습니다. 이름 하여 가루 삼겹살입니다. 잘게 자른 고기를 먹으면 배가 쉽게 차고 먹는 양 절제도 되니까, 아예 “극단적으로 가루로 갈아서 가루 삼겹살을 파는 점포를 사업화 하는 게 어떠냐” 라는 아이디어였죠.
실현 가능성을 논 외로 하면, 굉장히 우습고 재미있는 아이디어여서 생각에 많이 남았는데, 생각해보니 코딩에서는 저 개념이 굉장히 자주 쓰이고 있는 개념이라는 생각이 들었습니다.
간 고기를 덩어리 고기에 다시 묻혀서 굽고, 그렇게 만든 고기를 다시 갈아낸 뒤에 떡갈비로 다시 뭉쳐서 먹는 식의 뇌절 아이디어였지만, 프로그래밍에서는 이런 생각들이 절대 뇌절이 아니랍니다.
데이터를 갈아보자
서울특별시 빅데이터 캠퍼스
bigdata.seoul.go.kr
위 링크는 “서울시 대중교통 및 지하철 1회권 승하차 데이터” 를 제공하는 웹페이지 링크입니다.
위 스크린샷 처럼 각종 수많은 데이터들이 저장된 파일을 다운받을 수 있습니다.
대중교통에 대한 다양한 데이터들이 빼곡하게 들어차 있군요.
고기에서 가루로 갈아내기
고기를 가루로 만들면 가루 한 톨을 따로 분리해서 다룰 수 있듯이, 데이터도 가루로 만들면 하나씩 조회할 수 있는 상태가 됩니다.
주피터 노트북을 켜서 위 파일을 한번 파이썬으로 옮겨보도록 하겠습니다.
(pandas라는 라이브러리가 필요한데, 설치하는 방법은
https://hnanmal.tistory.com/entry/python-pip가-뭔데-이렇게-편하냐고요
상기의 링크를 참조하세요.)
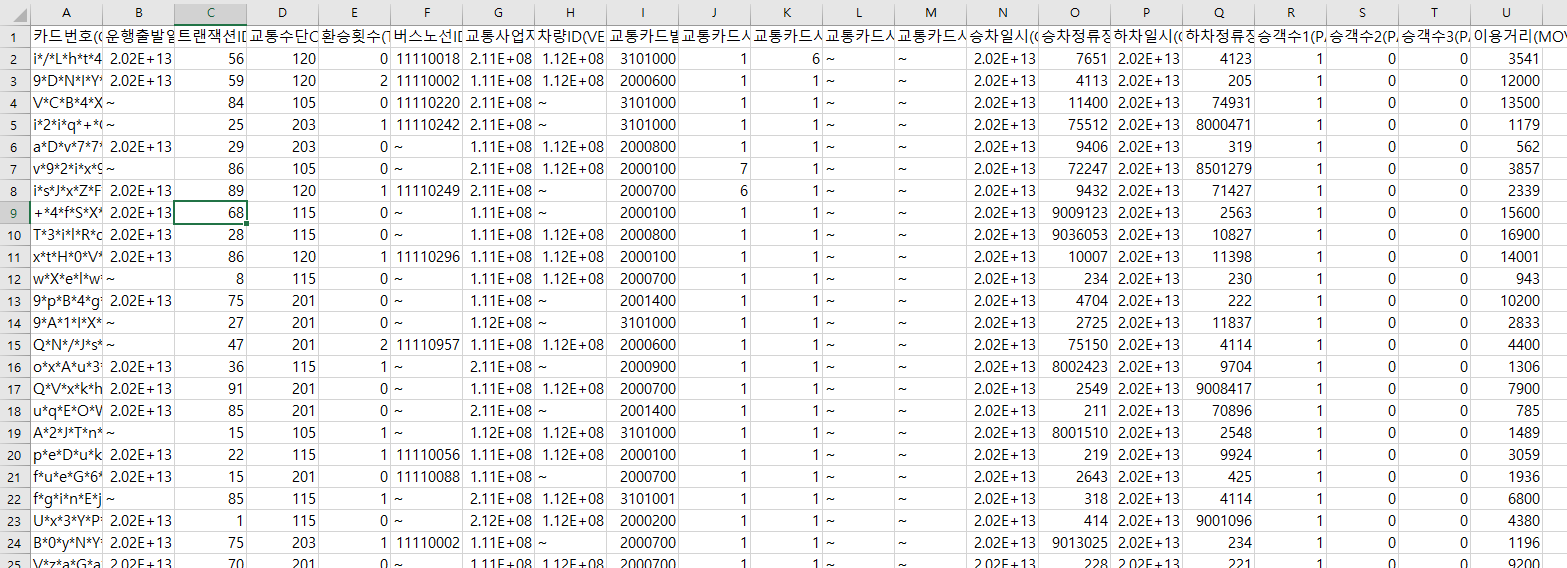
df는 dataframe을 줄여서 흔히 쓰는 약자이며, 엑셀 데이터 전체를 담아두는 변수명으로 흔히 사용됩니다.
주피터노트북 파일과 실습대상의 csv 파일을 동일 폴더에 넣고 작업하는 것이 편합니다. 그러면 위 그림처럼 파일 이름만 가지고 쉽게 불러오는 것이 가능하거든요.
여기서 df는 침착맨이 말한 고기 덩어리로 볼 수 있습니다. pandas 라이브러리를 통해 데이터를 읽어 들이는 순간부터 이미 가루로 만들어 조회할 수 있는 준비가 다 되었습니다.

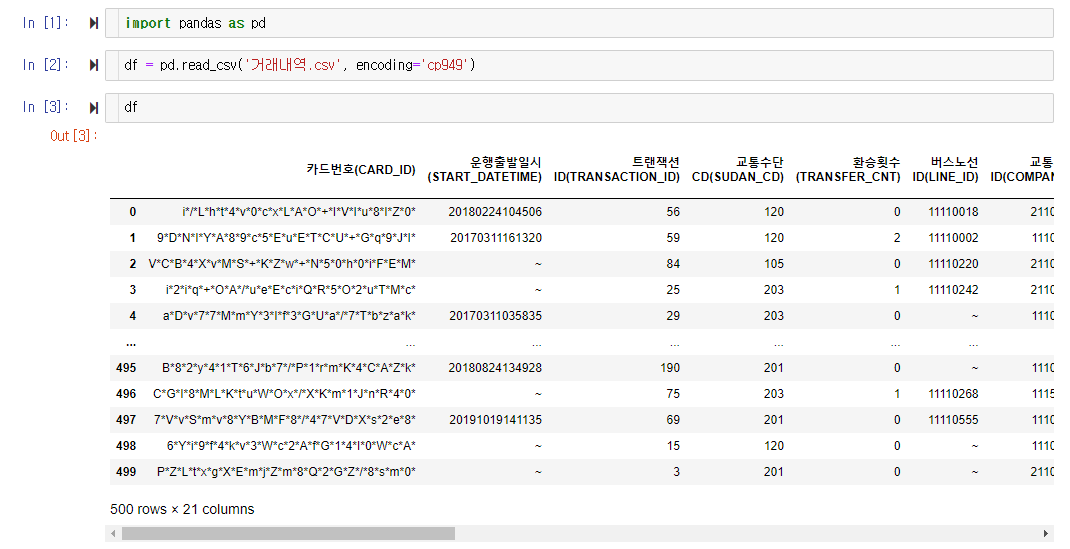
가루 조각 하나 씩 떼어서 살펴보는 방법은 loc 메소드 입니다. 데이터 프레임을 담고있는 변수명에 .을 찍고 loc라고 적은뒤 대괄호 안쪽에 몇번째 데이터를 확인하고 싶은지를 적으면, 위 그림처럼 데이터 중 해당부분만 추출되어 보여지게 됩니다. 위에서는 67번 인덱스의 데이터를 확인하고 있습니다.(데이터프레임의 인덱스가 0부터 시작한다는 것을 알고 계셔야 나중에 실수가 없습니다.)
뭉텅이로 잘라서 보관하는 것도 가능합니다.
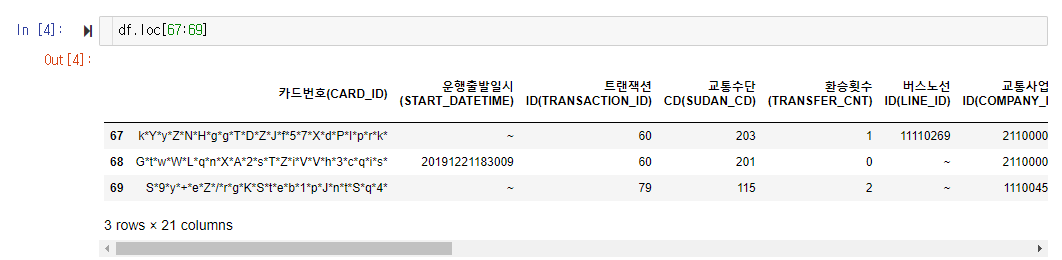
콜론(:)을 사용해서 범위로 데이터를 지정해 호출할 수도 있군요.
가루로 만든 고기를 다시 고기에 묻히기
이제 이 데이터에다 이해를 돕기 위해 특정 항목을 새롭게 추가해봅시다.

.columns라는 메서드는 각 칼럼의 이름들을 보여줍니다. 카드번호부터 시작해서 운행출발일시, 교통수단, 환승횟수 등의 다양한 칼럼들이 있군요. 저 중에 교통수단이 제일 우리가 알아보기 쉬운 내용이 있을 것 같으니 따로 때서 한번 봐야겠습니다.

앗, 그런데 교통수단 칼럼의 데이터들을 보니 알 수 없는 숫자들만 적혀있네요. 사실 이 데이터는 정규화(Normalize)된 데이터베이스의 양식을 따르고 있어서, 저 숫자 코드들이 각각 무엇을 가리키는 지는 다른 데이터로 분리하여 관리하고 있습니다.
아까 맨 처음 서울시 빅데이터 링크로 다시 가서 잘 살펴보면, “거래내역.csv” 말고도 “코드.csv” 라고 되어있는 파일이 있는 걸 볼 수 있습니다. 이 파일도 다운받아서 현재 작업중인 폴더에 다운 받으면 됩니다.
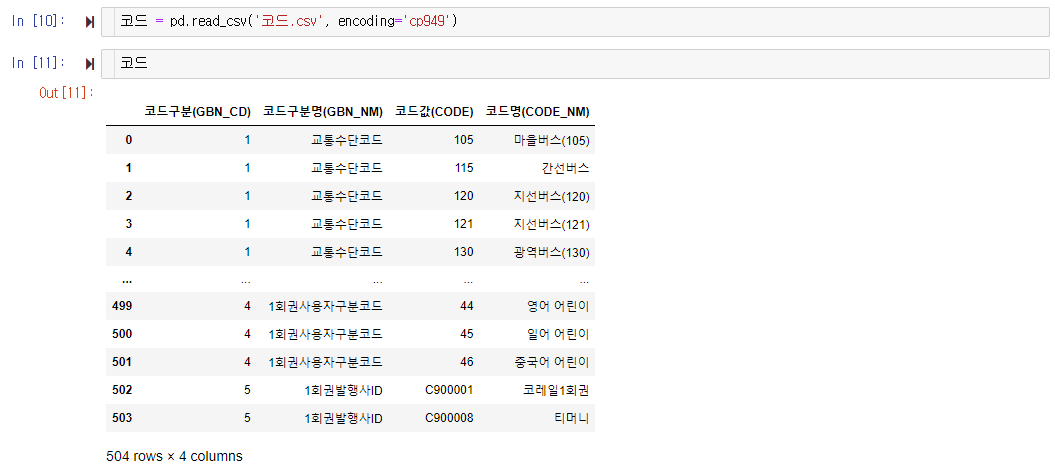
데이터를 불러오면 이렇게 됩니다. 교통수단코드도 있고, 1회권사용자구분코드 등등 여러가지 코드자료들이 있군요.
이중에 우리는 교통수단코드에만 관심이 있으니까, 불필요한 것들을 제외하고 따로 추려볼 필요가 있을 것 같아요.
교통수단코드 = 코드.loc[(코드['코드구분명(GBN_NM)'] == '교통수단코드'), :]추려내는 방법은 위와 같습니다. 데이터를 추려내는 기준을 보통 mask라고 부르는데, 위 코드에서는 괄호 안에 들어있는 부분이 mask에 해당합니다. 판다스 데이터프레임에서 masking 으로 데이터 추리는 방법은 상세하게 포스팅 할 예정이고, 또 이미 다른 분들이 더 이해하기 쉽게 작성한 글도 많으니 그걸 참조해서 공부하셔도 됩니다. 오늘은 전체 그림을 짚어낼 수 있을 정도로만 설명 드리겠습니다.
위 코드로 추려낸 결과를 한번 볼까요?
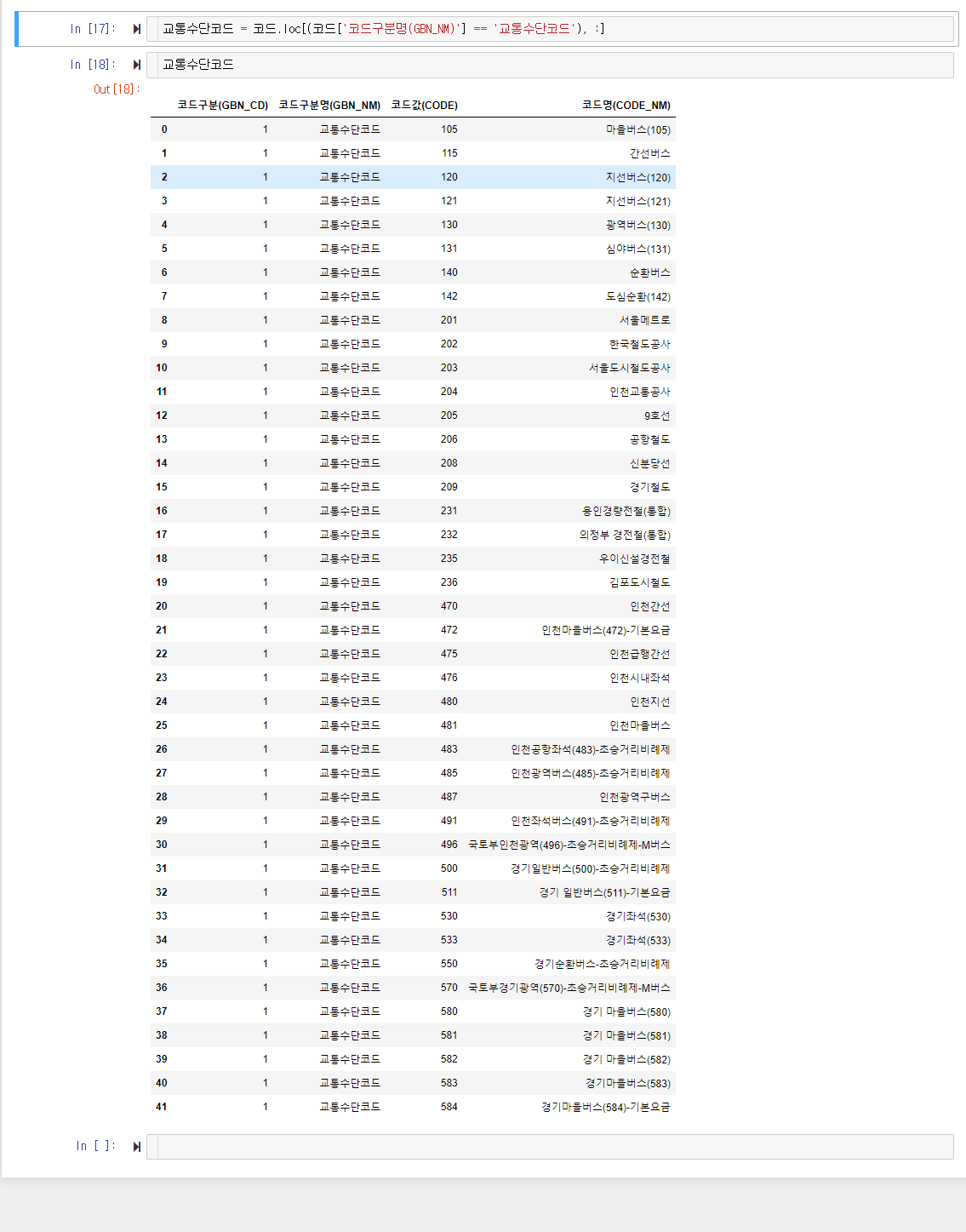
교통수단코드에 해당하는 데이터만 추려내는 데 성공했습니다.
이걸 활용해서 기존에 만들었던 df 에 새로운 칼럼을 덧붙여서 새로운 데이터 꾸러미를 만들어보고 싶군요.(가루로 만든 고기를 다시 고기에 묻히기)
일단 방금 만들었던 ‘교통수단코드’ 데이터 프레임에서 불필요한 부분을 제거해보겠습니다.

코드값 숫자와 코드명만 손쉽게 분리가 되었군요.(혹시나 어떤 코드를 썼는지 이해가 안돼도 그냥 보시면 됩니다. 흐름이 중요하거든요.)
이제 저는 딕셔너리라는 데이터형식을 하나 만들어서, df에 있는 교통수단 칼럼에 있는 숫자들에다가, 해당하는 코드명을 매칭시킬 수 있도록 준비를 하려고 합니다. 다른 방법도 있겠지만, 딕셔너리를 사용해서 데이터프레임 형식의 데이터를 다른 형식의 데이터로 바꾸는 것도 한번 경험해보겠습니다.
교통수단코드_정리.set_index('코드값(CODE)').T.to_dict('records')[0]위 코드를 사용하면 바로 데이터프레임이 딕셔너리로 바뀌는데요. 딕셔너리에서 “key 역할”을 해줄 칼럼을 ‘set_index’ 메서드로 선택하고, 행과 열을 ‘T’ 메서드로 전치 시킨 뒤에, ‘to_dict’ 메서드를 이용해 딕셔너리로 변환해 준 겁니다.
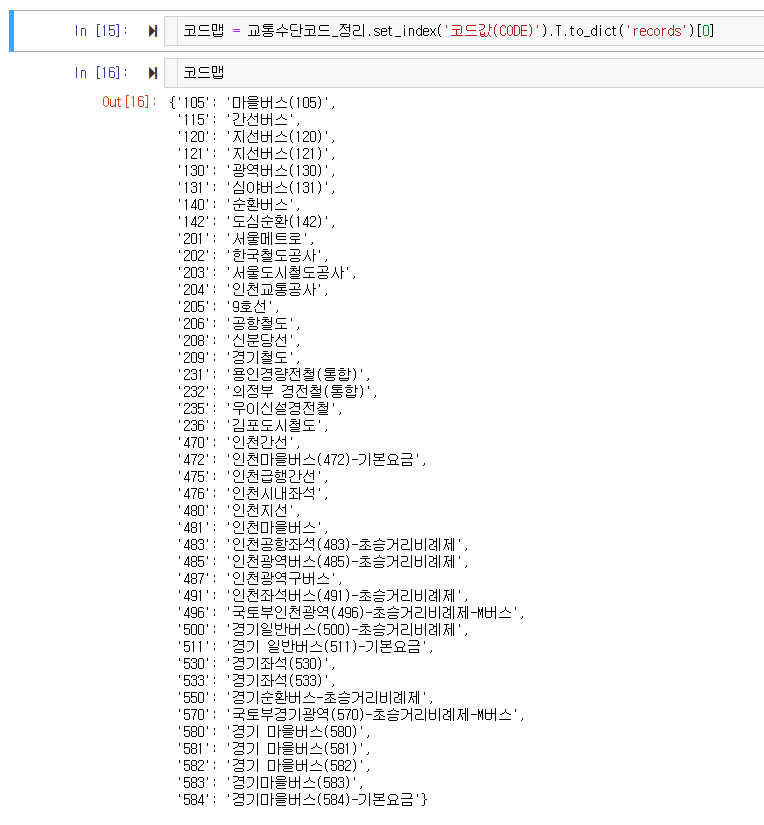
이렇게 변환됩니다. 깔끔하죠?
딕셔너리 데이터 형식에 대해서는 구글에서 검색해보셔도 되고, 아래 링크의 도입부분을 읽어보셔도 감이 좀 오실 거에요.
https://hnanmal.tistory.com/entry/다이나모에서-딕셔너리-활용하여-코드-리팩토링-하기
위 링크가 파이썬 관련 포스트는 아니지만, 딕셔너리 데이터에 대한 설명 만큼은 공통으로 이해하시면 됩니다.
자, ‘코드맵’ 이라는 변수에 딕셔너리를 저장해 두었습니다. 이제 이런 것을 할 수 있습니다.

딕셔너리 뒤에 대괄호를 열고 key 중 하나를 넣어 주면, 그 key에 해당하는 value를 반환해 줍니다.
이걸 이용해서 df 에 있던 교통수단 코드 숫자들을 읽어온 뒤에, 그것들이 코드맵 중 어떤 값에 해당하는지 새롭게 리스트를 한번 만들어 보겠습니다.

아까 df에서 '교통수단CD(SUDAN_CD)’ 칼럼에 있던 데이터들만 리스트로 분리해 냈습니다. 여기에 대응되는 코드명들을 뽑으려면 어떻게 해야 할까요?
list(map(lambda x: 코드맵[str(x)], 교통수단_numbers))이렇게 코드를 작성하면 됩니다.
for 문이 더 익숙하신 분들은 아래 스크린샷을 참고하시면 됩니다.

new_values 라는 변수에 새로 만들어낸 리스트를 저장해둡시다.
이제 남은 작업은 기존의 df 에 새로 만들어낸 리스트 데이터를 삽입해주는 것 만 남았군요. insert 메서드를 사용하면 됩니다.
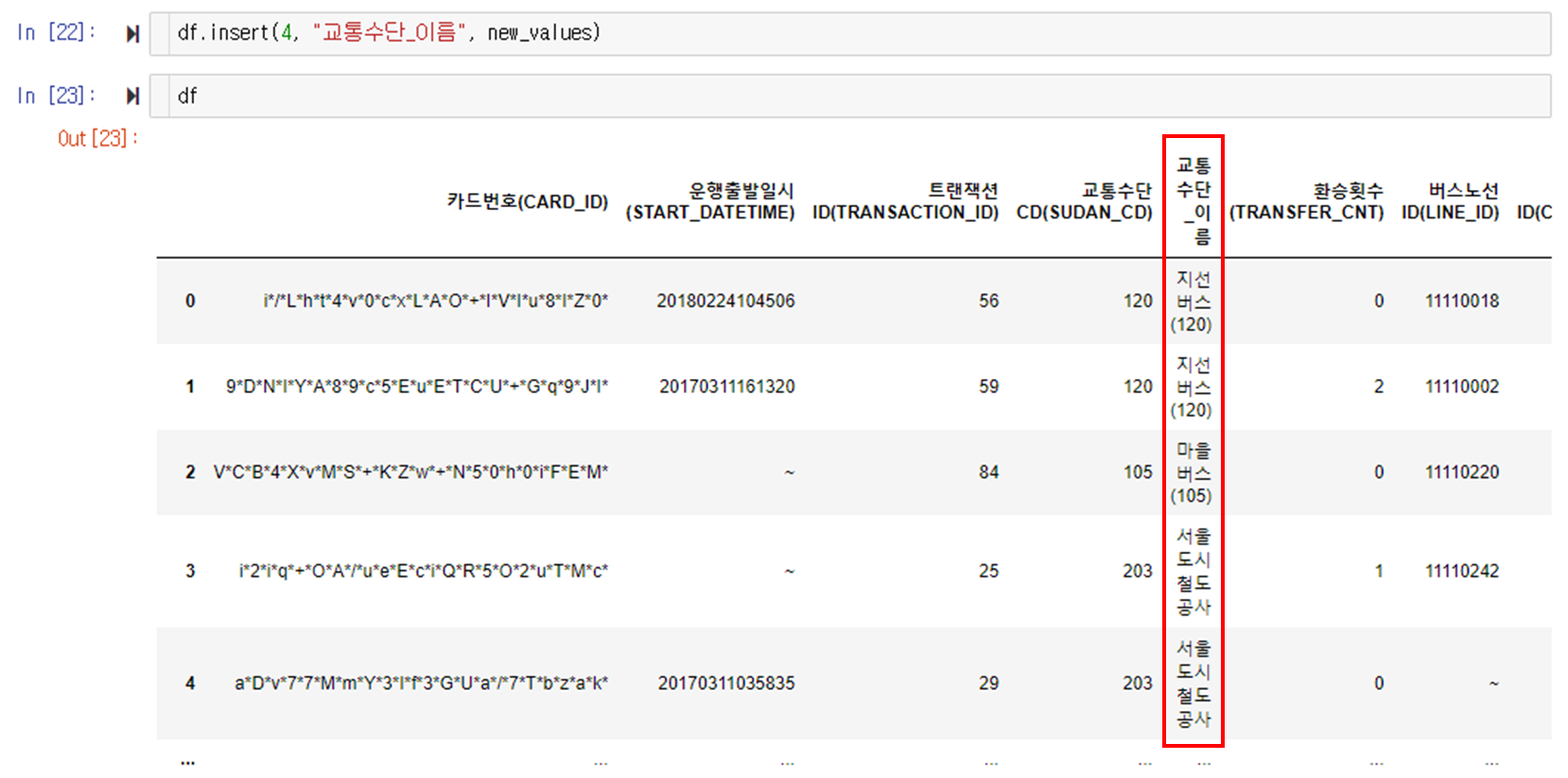
짜잔, df에 새로운 칼럼이 하나 생기고, 교통수단이 숫자가 아닌 이름으로 적히게 되었네요.
가루 묻은 고기를 다시 뭉쳐 떡갈비 만들기
이제 아까 만들었던 df 데이터프레임에서 카드번호, 운행출발일시, 교통수단_이름 이 세가지 칼럼만 가지고, 딕셔너리 형태의 데이터를 새로 만들어 보겠습니다. 가루를 다시 뭉쳐 떡갈비를 만드는 셈이죠.
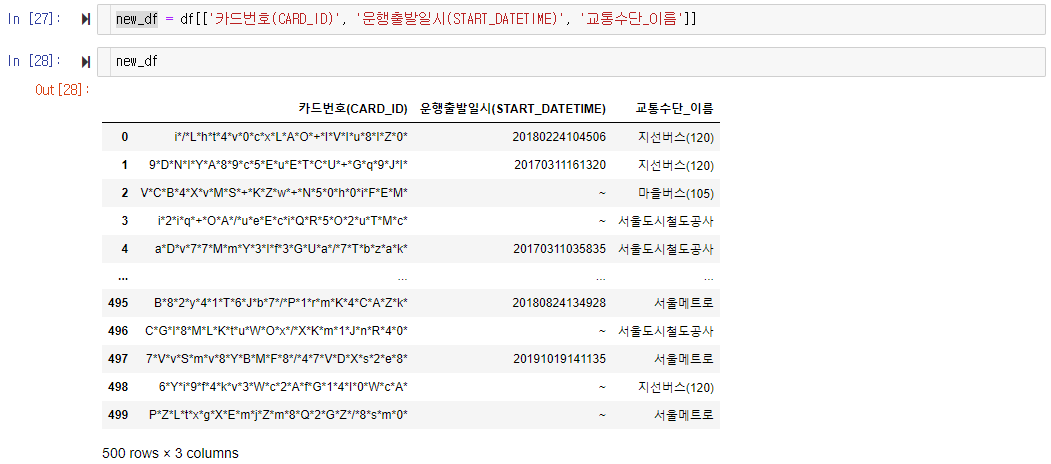
3가지 칼럼이 있는 500행 짜리 데이터프레임으로 재편 되었습니다.
이 데이터 프레임을 떡갈비처럼 뭉쳐서 딕셔너리로 바꿔볼까요?
new_df = df[['카드번호(CARD_ID)', '운행출발일시(START_DATETIME)', '교통수단_이름']]
new_dictionary = new_df.set_index('카드번호(CARD_ID)').T.to_dict()위의 코드를 작성하면 됩니다.
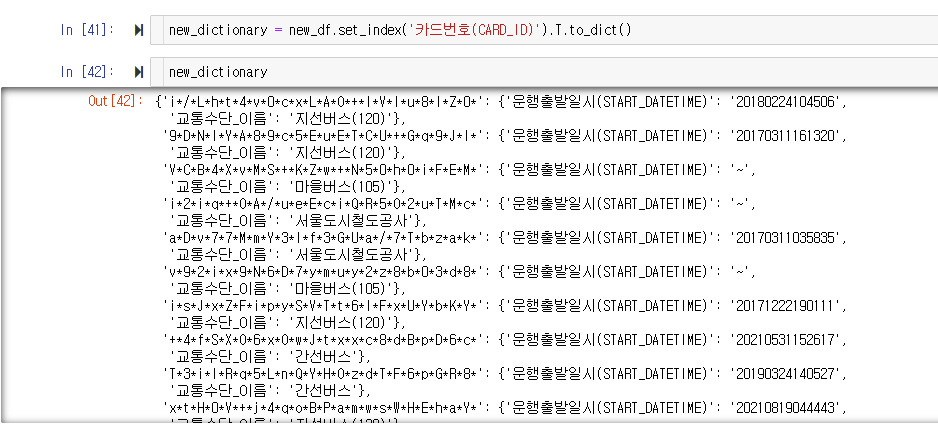
코드를 작성하고 결과를 보니 뭔가 딕셔너리가 생겼는데, 어지럽게 적혀있죠?
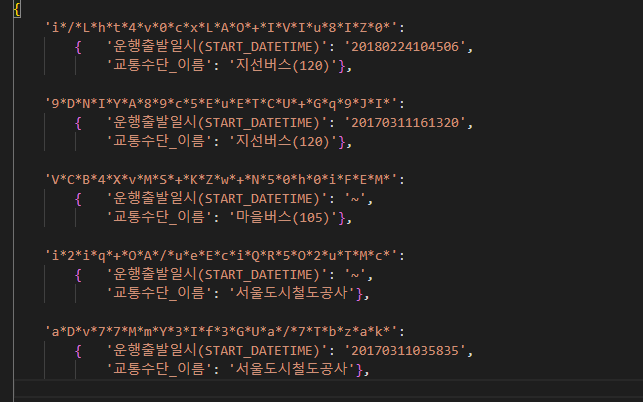
Visual Studio Code 프로그램으로 옮겨서 보면 이렇게 들여쓰기 된 형태로 볼 수 있습니다.
카드이름이 key 값이고, 그에 해당하는 value가 다시 ‘운행출발일시(START_DATETIME)’와 ‘교통수단_이름’을 key 값으로 하는 딕셔너리를 이루고 있죠?
이렇게 중첩된 딕셔너리 구조를 형성하는 데이터로 최종 완성했습니다.
가루 떡갈비 완성입니다.
결론
과정을 쭉 훑어보니 어떠신가요? 코드 한줄 한줄 까지 파악은 안되더라도, 어떻게 코딩으로 기존의 데이터를 이용해 새로운 데이터를 만들어내고, 기존 데이터에 다시 편입시키며 그 이후 새로운 형식으로 빚어낼 수 있는지 감이 오실거라 생각합니다.
감이 오신 분들은 이 포스트에 적힌 내용을 천천히 처음부터 한번 따라해보세요. 서울시 빅데이터 캠퍼스에 있는 데이터들은 생각보다 가지고 놀기에 재미있는 데이터들입니다. 이 데이터들을 통해 포스트의 내용을 실습해본다면, Pandas 라이브러리 이용법과 데이터의 활용에 대해 숙련도를 올릴 수 있는 계기가 될 거라고 생각합니다.